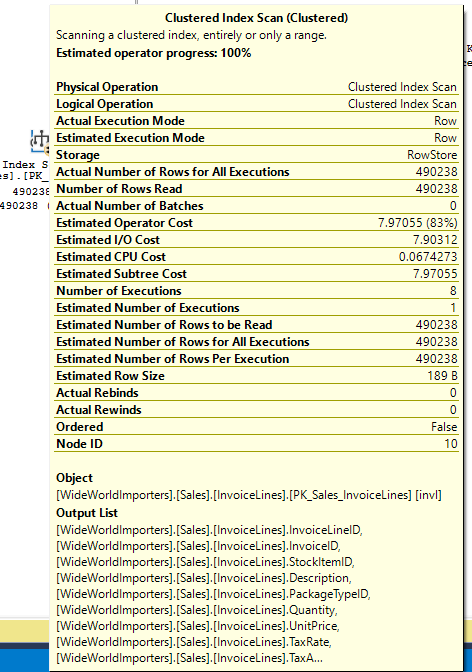
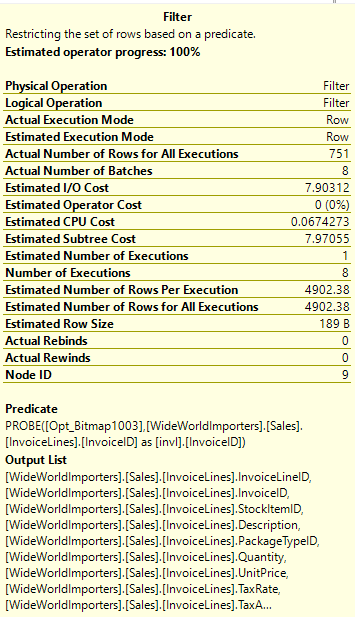
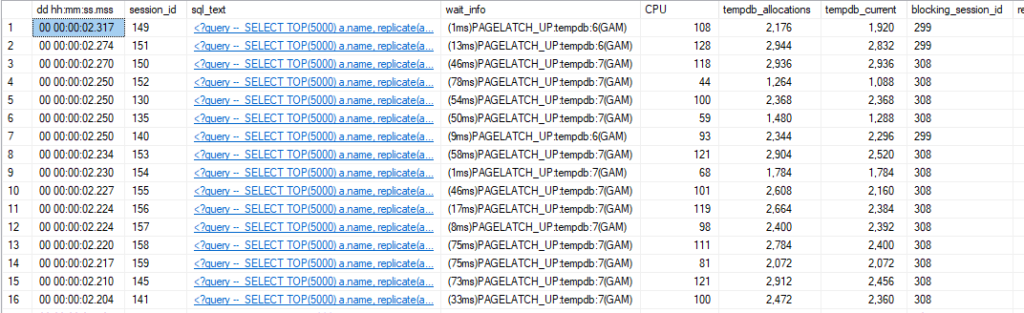
Tempdb contention has long been an issue in SQL Server, and there are many blogs on the issue already. But I wanted to add one more mainly to highlight the improvements in recent versions of SQL Server
Tempdb contention is most often discussed in as relating to the creation of temp tables (and other objects) in tempdb. If you are experiencing this you will see PAGELATCH_EX or PAGELATCH_SH waits, frequently with wait resources like 2:1:1 or 2:1:3. This indicates contention in database 2 (tempdb), page 1 (the first data file in tempdb), and one of the PFS, GAM, or SGAM pages (which are pages 1, 2, and 3 respectively). Tempdb files of sufficient size will have additional PFS, GAM, and SGAM pages at higher page numbers, but 1 and 3 are the pages most often referenced.
Temp tables aren’t the only objects being created in tempdb. Table variables are as well unless they are memory-optimized. There are also worktables for sorts, spools, and cursors. Hash operations can spill to disk and are written into tempdb. Row versions are written into tempdb for things like read committed snapshot isolation, and triggers make use of row versioning as well. For more details, check out this excellent post by David Pless.
Before recent releases, there were three main suggestions for reducing tempdb contention.
- Trace flags (1118 and 1117)
- More tempdb files
- Create fewer objects in tempdb
Honestly, I don’t think the third was even included in a lot of the blogs on the subject, and it is very important. Many of the actions that use tempdb can’t be avoided, but I tend to use memory-optimized table variables instead of temp tables the vast majority of the time.
In one case a few years ago, I replaced the memory-optimized table variables in one very frequently executed stored procedure with temp tables to see if using temp tables would result in better execution plans. This procedure was executed about 300 million times per day across several SQL Server instances using similar databases, and the procedure used 4 temp tables. The plans didn’t matter; creating 1.2 billion more temp tables per day added far too much tempdb contention.
But the main point of this post is to help everyone catch up on the topic, and see how more recent versions of SQL Server improve on this issue.
Improvements in SQL Server 2016
SQL Server 2016 introduced several improvements that help reduce tempdb contention.
The most obvious is that setup will create multiple files by default, one per logical server up to eight. That bakes in one of the main recommendations for reducing tempdb contention, so it’s a welcome improvement.
There are also behavior changes that include the behavior of trace flags 1117 and 1118. All tempdb data files grow at the same time and by the same amount by default, which removes the need for trace flag 1117. And all tempdb allocations use uniform extents instead of mixed extents, removing the need for trace flag 1118.
So, that’s another recommendation for reducing tempdb contention already in place.
Several other changes also improve caching (reducing page latch and metadata contention), reduce the logging for tempdb operation, and reduce the usage of update locks.
For the full list, check here.
Improvements in SQL Server 2019
The big change here is the introduction of memory-optimized tempdb metadata. The documentation here says that this change (which is not enabled by default, you will need to run an ALTER SERVER CONFIGURATION statement and restart) “effectively removes” the bottleneck from tempdb metadata contention.
However, this post by Marisa Mathews indicates the memory-optimized tempdb metadata improvement in SQL Server 2019 removed most contention in PFS pages caused by concurrent updates. This is done by allowing the updates to occur with a shared latch (see the “Concurrent PFS updates” entry here).
One thing I would point out is that the metadata is being optimized here; the temp tables you create are not memory-optimized and will still be written to the storage under tempdb as usual.
Improvements in SQL Server 2022
The post above also indicates that SQL Server 2022 reduces contention in the GAM and SGAM pages by allowing these pages to be updated with a shared lock rather than an update log.
The issue with the PFS, GAM, and SGAM pages has always been the need for an exclusive latch on those pages when an allocation takes place. If 20 threads are trying to create a temp table, 19 of them get to wait. The suggestion to add more data files to tempdb was a way to get around access to these pages being serialized; adding more files gives you more of these pages to spread the allocation operations across.
In Summary
The gist is that tempdb contention has been nearly eliminated in SQL Server 2022. There are still several other actions that use tempdb, and you may see contention if have a niche workload or use a lot of worktables.
Hopefully, this post will help you decide if it’s time for an upgrade. If you have been seeing tempdb contention on these common pages, the latest release should be a major improvement.
Feel free to contact me with any questions or let me know of any suggestions you may have for a post.
Other links
Wanted to point out a few more good articles and a video on the subject that you may enjoy.